Abstract
Method
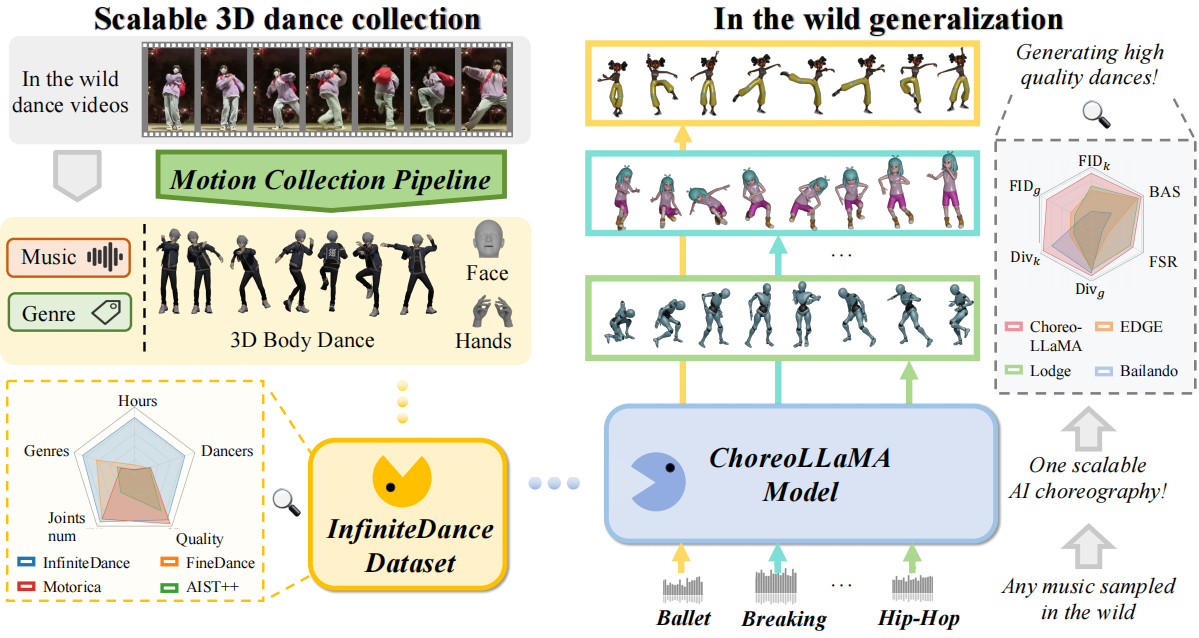
In order to achieve scalable and generalizable 3D dance generation, we design a two-pronged approach that addresses both data quality and model architecture.
Data Pipeline with Foot Restoration
We develop a fully automated pipeline that reconstructs high-fidelity 3D dance motions from monocular videos. To eliminate physical artifacts prevalent in existing reconstruction methods, we introduce a Foot Restoration Diffusion Model (FRDM) guided by foot-contact and geometric constraints. This ensures physical plausibility while preserving kinematic smoothness and expressiveness, resulting in a diverse, high-quality multimodal 3D dance dataset.
Choreographic LLaMA Architecture
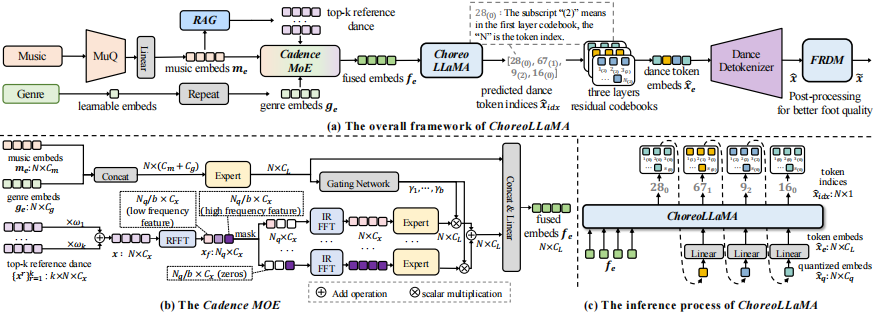
We propose Choreographic LLaMA (ChoreoLLaMA), a scalable LLaMA-based architecture for 3D dance generation. To enhance robustness under unfamiliar music conditions, we integrate a retrieval-augmented generation (RAG) module that injects reference dance as a prompt. Additionally, we design a slow/fast-cadence Mixture-of-Experts (MoE) module that enables ChoreoLLaMA to smoothly adapt motion rhythms across varying music tempos.
Results
As shown in the following videos (Please unmute for music), ChoreoLLaMA from InfiniteDance can generate high-quality 3D dances from given music with improved generalization capabilities.